Note
Go to the end to download the full example code.
ハイパーパラメータ最適化の結果を可視化する
Optuna では optuna.visualization モジュールで様々な可視化機能を提供しており、
最適化の結果を視覚的に分析することができます。
なお、本チュートリアルでは Plotly のインストールが必要です。
$ pip install plotly
# Jupyter Notebook で本チュートリアルを実行する場合に必要です。
$ pip install nbformat
Plotly の代わりに Matplotlib を使用したい場合、以下のコマンドを実行してください:
$ pip install matplotlib
本チュートリアルでは、FashionMNIST データセットに対する PyTorch モデルの最適化結果を可視化しながら、 このモジュールの使い方を説明します。
多目的最適化の結果を可視化する場合 (optuna.visualization.plot_pareto_front() の使用) は、
Optuna による多目的最適化 のチュートリアルを参照してください。
Note
Optuna Dashboard を使用すると、 最適化の履歴やハイパーパラメータの重要度、ハイパーパラメータ間の関係などを グラフや表で確認できます。 最適化結果を保存するには RDB バックエンド を使用し、 以下のコマンドを実行して Optuna Dashboard を起動してください。
$ pip install optuna-dashboard
$ optuna-dashboard sqlite:///example-study.db
詳細は GitHub リポジトリ をご覧ください。
スタディの管理 |
インタラクティブなグラフで可視化 |
|---|---|
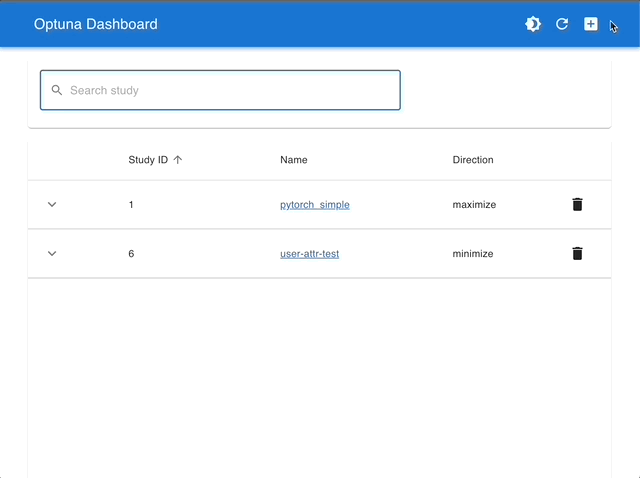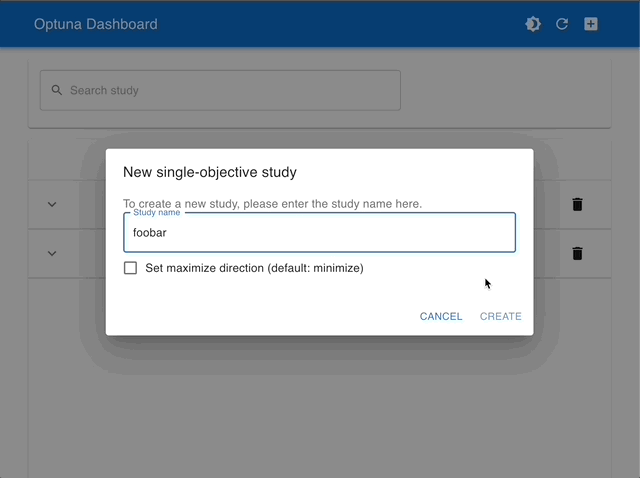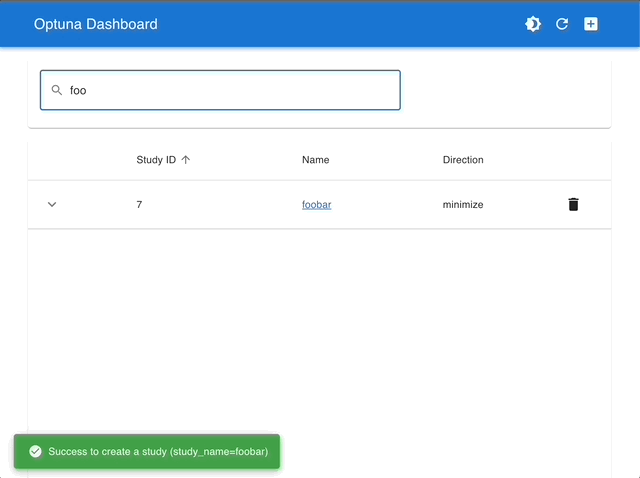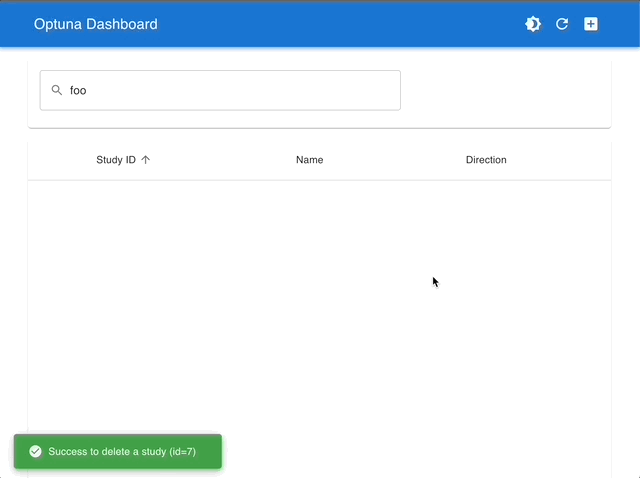
|
|
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import optuna
# 以下の例では、`optuna.visualization` を `optuna.visualization.matplotlib` に置き換えることで、
# Plotly の代わりに Matplotlib を使用できます。
from optuna.visualization import plot_contour
from optuna.visualization import plot_edf
from optuna.visualization import plot_intermediate_values
from optuna.visualization import plot_optimization_history
from optuna.visualization import plot_parallel_coordinate
from optuna.visualization import plot_param_importances
from optuna.visualization import plot_rank
from optuna.visualization import plot_slice
from optuna.visualization import plot_timeline
SEED = 13
torch.manual_seed(SEED)
DEVICE = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
DIR = ".."
BATCHSIZE = 128
N_TRAIN_EXAMPLES = BATCHSIZE * 30
N_VALID_EXAMPLES = BATCHSIZE * 10
def define_model(trial):
n_layers = trial.suggest_int("n_layers", 1, 2)
layers = []
in_features = 28 * 28
for i in range(n_layers):
out_features = trial.suggest_int("n_units_l{}".format(i), 64, 512)
layers.append(nn.Linear(in_features, out_features))
layers.append(nn.ReLU())
in_features = out_features
layers.append(nn.Linear(in_features, 10))
layers.append(nn.LogSoftmax(dim=1))
return nn.Sequential(*layers)
# モデルの学習と評価を定義します。
def train_model(model, optimizer, train_loader):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.view(-1, 28 * 28).to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
F.nll_loss(model(data), target).backward()
optimizer.step()
def eval_model(model, valid_loader):
model.eval()
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(valid_loader):
data, target = data.view(-1, 28 * 28).to(DEVICE), target.to(DEVICE)
pred = model(data).argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
accuracy = correct / N_VALID_EXAMPLES
return accuracy
目的関数を定義します。
def objective(trial):
train_dataset = torchvision.datasets.FashionMNIST(
DIR, train=True, download=True, transform=torchvision.transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(
torch.utils.data.Subset(train_dataset, list(range(N_TRAIN_EXAMPLES))),
batch_size=BATCHSIZE,
shuffle=True,
)
val_dataset = torchvision.datasets.FashionMNIST(
DIR, train=False, transform=torchvision.transforms.ToTensor()
)
val_loader = torch.utils.data.DataLoader(
torch.utils.data.Subset(val_dataset, list(range(N_VALID_EXAMPLES))),
batch_size=BATCHSIZE,
shuffle=True,
)
model = define_model(trial).to(DEVICE)
optimizer = torch.optim.Adam(
model.parameters(), trial.suggest_float("lr", 1e-5, 1e-1, log=True)
)
for epoch in range(10):
train_model(model, optimizer, train_loader)
val_accuracy = eval_model(model, val_loader)
trial.report(val_accuracy, epoch)
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return val_accuracy
study = optuna.create_study(
direction="maximize",
sampler=optuna.samplers.TPESampler(seed=SEED),
pruner=optuna.pruners.MedianPruner(),
)
study.optimize(objective, n_trials=30, timeout=300)
0%| | 0.00/26.4M [00:00<?, ?B/s]
0%| | 32.8k/26.4M [00:00<03:17, 134kB/s]
0%| | 65.5k/26.4M [00:00<03:18, 133kB/s]
0%| | 131k/26.4M [00:00<02:16, 193kB/s]
1%| | 229k/26.4M [00:00<01:35, 273kB/s]
2%|▏ | 459k/26.4M [00:01<00:51, 507kB/s]
3%|▎ | 918k/26.4M [00:01<00:24, 1.06MB/s]
7%|▋ | 1.84M/26.4M [00:01<00:12, 1.98MB/s]
14%|█▍ | 3.67M/26.4M [00:01<00:06, 3.78MB/s]
28%|██▊ | 7.34M/26.4M [00:02<00:02, 7.32MB/s]
41%|████ | 10.8M/26.4M [00:02<00:01, 9.46MB/s]
54%|█████▍ | 14.3M/26.4M [00:02<00:01, 10.9MB/s]
65%|██████▍ | 17.2M/26.4M [00:02<00:00, 11.0MB/s]
78%|███████▊ | 20.5M/26.4M [00:03<00:00, 11.8MB/s]
92%|█████████▏| 24.4M/26.4M [00:03<00:00, 13.0MB/s]
100%|██████████| 26.4M/26.4M [00:03<00:00, 7.58MB/s]
0%| | 0.00/29.5k [00:00<?, ?B/s]
100%|██████████| 29.5k/29.5k [00:00<00:00, 120kB/s]
100%|██████████| 29.5k/29.5k [00:00<00:00, 120kB/s]
0%| | 0.00/4.42M [00:00<?, ?B/s]
1%| | 32.8k/4.42M [00:00<00:33, 131kB/s]
1%|▏ | 65.5k/4.42M [00:00<00:33, 130kB/s]
3%|▎ | 131k/4.42M [00:00<00:22, 190kB/s]
5%|▌ | 229k/4.42M [00:01<00:15, 268kB/s]
10%|█ | 459k/4.42M [00:01<00:07, 500kB/s]
21%|██ | 918k/4.42M [00:01<00:03, 1.04MB/s]
41%|████▏ | 1.84M/4.42M [00:01<00:01, 1.95MB/s]
83%|████████▎ | 3.67M/4.42M [00:01<00:00, 3.72MB/s]
100%|██████████| 4.42M/4.42M [00:02<00:00, 2.19MB/s]
0%| | 0.00/5.15k [00:00<?, ?B/s]
100%|██████████| 5.15k/5.15k [00:00<00:00, 24.7MB/s]
プロット関数
最適化履歴を可視化します。詳細は plot_optimization_history() を参照してください。
plot_optimization_history(study)
トライアルの学習曲線を可視化します。詳細は plot_intermediate_values() を参照してください。
plot_intermediate_values(study)
高次元パラメータの関係を可視化します。詳細は plot_parallel_coordinate() を参照してください。
plot_parallel_coordinate(study)
可視化するパラメータを選択します。
plot_parallel_coordinate(study, params=["lr", "n_layers"])
ハイパーパラメータの関係を可視化します。詳細は plot_contour() を参照してください。
plot_contour(study)
可視化するパラメータを選択します。
plot_contour(study, params=["lr", "n_layers"])
ハイパーパラメータをスライスプロットとして可視化します。詳細は plot_slice() を参照してください。
plot_slice(study)
可視化するパラメータを選択します。
plot_slice(study, params=["lr", "n_layers"])
パラメータの重要度を可視化します。詳細は plot_param_importances() を参照してください。
plot_param_importances(study)
ハイパーパラメータの重要度を用いて、トライアルの実行時間に影響を与えているハイパーパラメータを特定します。
optuna.visualization.plot_param_importances(
study, target=lambda t: t.duration.total_seconds(), target_name="duration"
)
経験的分布関数を可視化します。詳細は plot_edf() を参照してください。
plot_edf(study)
目的値で色分けした散布図でパラメータの関係を可視化します。詳細は plot_rank() を参照してください。
plot_rank(study)
実行されたトライアルの最適化タイムラインを可視化します。詳細は plot_timeline() を参照してください。
plot_timeline(study)
生成された図のカスタマイズ
optuna.visualization および optuna.visualization.matplotlib では、関数が編集可能な図オブジェクトを返します:
モジュールに応じて plotly.graph_objects.Figure または matplotlib.axes.Axes です。
これにより、ユーザーは可視化ライブラリの API を使用して、生成された図を必要に応じて変更できます。
以下の例では、Plotly ベースの plot_intermediate_values() で描画された図のタイトルを手動で置き換えています。
fig = plot_intermediate_values(study)
fig.update_layout(
title="FashionMNIST 分類のためのハイパーパラメータ最適化",
xaxis_title="エポック",
yaxis_title="検証精度",
)
Total running time of the script: (1 minutes 37.331 seconds)